

报告地点:舜耕校区4号楼511会议室
报告时间:2025年7月13日(星期日)14:30—17:30
主办单位:亚洲博彩平台网址大全 、可信人工智能实验室
协办单位:科研处,黄河流域生态统计协同创新中心、现代统计交叉科学重点实验室、统计学博士后科研流动站
一、青年教师工作论文报告
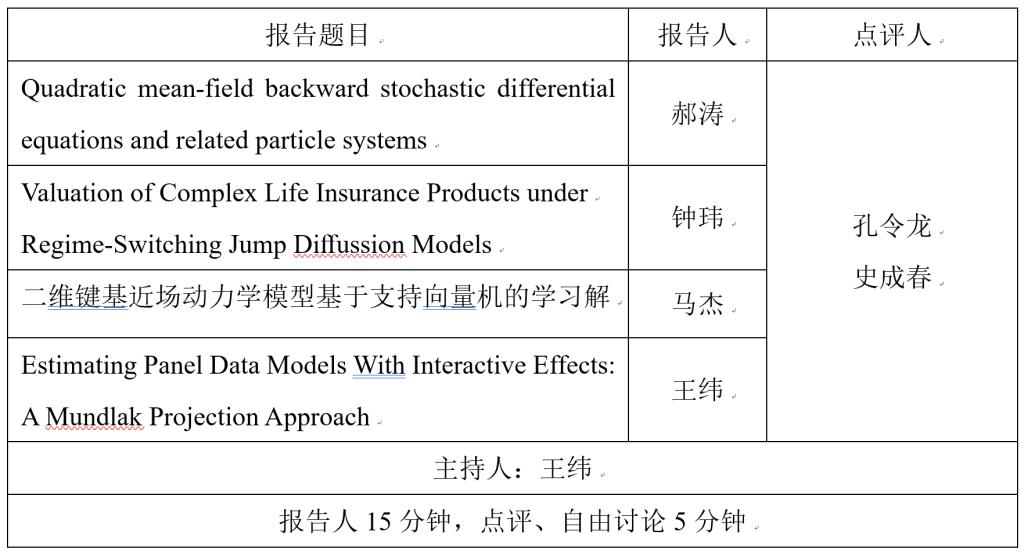
二、特邀专家报告
报告题目1:Distributional Reinforcement Learning with Regularized Wasserstein Loss
报告人1:孔令龙 教授 (加拿大阿尔伯塔大学)
报告人简介:Dr. Linglong Kong is a Professor in the Department of Mathematical and Statistical Sciences at the University of Alberta, holding a Canada Research Chair in Statistical Learning and a Canada CIFAR AI Chair. He is a Fellow of the American Statistical Association (ASA) and the Alberta Machine Intelligence Institute (Amii), with over 120 peer-reviewed publications in leading journals and conferences such as AOS, JASA, JRSSB, NeurIPS, ICML, and ICLR. Dr. Kong received the 2025 CRM-SSC Prize for outstanding research in Canada. He serves as Associate Editor for several top journals, including JASA and AOAS, and has held leadership roles within the ASA and the Statistical Society of Canada. Dr. Kong’s research interests include high-dimensional and neuroimaging data analysis, statistical machine learning, robust statistics, quantile regression, trustworthy machine learning, and artificial intelligence for smart health.
摘要:The empirical success of distributional reinforcement learning (RL) highly relies on the choice of distribution divergence equipped with an appropriate distribution representation. In this paper, we propose Sinkhorn distributional RL (Sinkhorn$D R L$ ), which leverages Sinkhorn divergence-a regularized Wasserstein loss-to minimize the difference between current and target Bellman return distributions. Theoretically, we prove the contraction properties of SinkhornDRL, aligning with the interpolation nature of Sinkhorn divergence between Wasserstein distance and Maximum Mean Discrepancy (MMD). The introduced SinkhornDRL enriches the family of distributional RL algorithms, contributing to interpreting the algorithm behaviors compared with existing approaches by our investigation into their relationships. Empirically, we show that SinkhornDRL consistently outperforms or matches existing algorithms on the Atari games suite and particularly stands out in the multi-dimensional reward setting.
报告题目2:Doubly Robust Alignment for Large Language Models
报告人2:史成春 副教授 (英国伦敦政治经济博彩平台网址大全 )
报告人简介:Dr. Chengchun Shi is an Associate Professor at London School of Economics and Political Science. He is serving as the associate editors of top statistics journals JRSSB, JASA. His research focuses on reinforcement learning, with applications to healthcare, ridesharing, video-sharing and neuroimaging. He has published over 50 papers, in both highly-ranked machine learning conferences (e.g., NeurIPS, ICML, KDD, AISTATS) and statistics journals (e.g., JASA, JRSSB, AoS). He was the recipient of the Royal Statistical Society Research Prize in 2021 and IMS Tweedie Award in 2024.
摘要:This paper studies reinforcement learning from human feedback (RLHF) for aligning large language models with human preferences. While RLHF has demonstrated promising results, many algorithms are highly sensitive to misspecifications in the underlying preference model (e.g., the Bradley-Terry model), the reference policy, or the reward function, resulting in undesirable fine-tuning. To address model misspecification, we propose a doubly robust preference optimization algorithm that remains consistent when either the preference model or the reference policy is correctly specified (without requiring both). Our proposal demonstrates superior and more robust performance than stateof-the-art algorithms, both in theory and in practice. The code is available at https: //github.com/DRPO4LLM/DRPO4LLM